VirtuWall



Nick Crews / July 01, 2021
15 min read • NaN views
This is an project that I worked on in the fall of 2015. I managed to get basic climber detection, as you can see in the video below:
I also worked on automatic hold detection (holds are the colorful plastic shapes that you grab onto), and you can see a result of that below:


As you can see, it's not perfect, but not too shabby. My goal was to emulate something like the complete augmented reality climbing wall in the video below:
I started this project because this looked like an awesome mixture of some of my favorite things: climbing, computer science, and game design. I was also excited because I have always been fascinated by computer vision, and this seemed like an excellent introduction.
All I needed to emulate these projects was a depth camera, a projector, and a climbing wall. I knew that the Computer Science department at CC has a Xbox Kinect available to use as a depth camera, and I could borrow a projector from somewhere I was sure. Thanks to David Crye and Ryan Hammes from CC Outdoor Education, I could use the Ritt Kellogg Climbing Gym in the campus fitness center whenever it wasn't open to the public.
The code that powers this project, archived at the time of writing this, can be found on Github. I wrote this back in 2015 as a sophomore, so the code can be a little clunky at times. I have slow internet at home, so the recordings in the /out directory aren't uploaded yet. If you want to follow the most current version of the project, that master branch should also be viewable.
Setup
The Xbox Kinect I used was a first generation model 1473, which means that it uses an infrared (IR) projector and camera, offset from each other, to create a stereoscopic depth image, similar to as we do with our two eyes. This depth image is calculated on the Kinect from the raw IR feed with embedded hardware, and can be requested as an 11 bit 480x640 image. You can watch this really good explanation video. The Kinect can also stream the 480x640 raw feed from the IR camera, and a 3 channel, 8 bit, 480x640 feed from another built in RGB (visible light) camera.
I chose to use Python because of its ease of use, and the computer vision libraries available. The primary libraries I used were NumPy, for fast and easy operations on matrices and images, OpenCV, which is a free computer vision library. To interface with the Kinect, I used OpenKinect.org's libfreenect library, which has a nice wrapper for Python that interfaces directly with NumPy. For visualizing image histograms, and other plotting, I used the library MatPlotLib.
In the climbing gym, I used a flat 15x15 foot section of wall, which was covered in a normal distribution of routes.
Recording and Playing Video
One of the first orders of business was making it so I didn't have to work in the gym all the time. I wanted an easy way to save and replay video captured from the kinect in a way that replicated a live feed from the Kinect exactly. To save video, I wrote a VideoSaver class, which takes individual frames and saves them to numbered PNG files in a directory. This method is uglier than saving frames directly to a video, but I had trouble finding a library that could write to a lossless video format. Without a lossless video format, the frames would be compressed and distorted, making tests with a saved recording and the live feed from the Kinect inconsistent. PNG images have no compression, making them perfectly emulate a live feed. Plus, using individual images made it easier to inspect or edit them manually if I wanted. Also, by numbering individual frames this way, depth and RGB frames could be related to each other. Then, when we overlay them or compare them, we are actually using frames recorded from the same instant.
I also wrote a VideoSource class that could read from either the Kinect or these saved recordings, making them completely indistinguishable, as I wanted. These two classes, along with some other utility i/o methods make up the inputoutput.py module.
Below is an example of a recording that I used. The compression to a GIF animation lowered the quality a little bit, but the original PNGs were also fairly noisy. The camera on the Kinect just isn't very good. Also, notice how I'm not wearing pants. I discovered that the black jeans that I was wearing absorbed the IR light from the projector, so the depth image was useless. My black socks and underwear showed up fine though, so it must be something to do with the material.
Depth Normalization
Another problem I had to deal with was converting the depth frames from the Kinect to a format that was useful. The raw NumPy array that libfreenect gives you is a single channel 16 bit unsigned integer array, of which only the first 11 bits are actually used. Normal pixels can have values ranging from 0 to 2^10-1 = 1023, with smaller numbers representing things that are closer. A pixel with value of 2^11-1 = 2047 signifies an error, where the object is either too close or too far away from the Kinect to be detected properly, or there is some other problem, such as the IR light is reflected by some nasty material (pants!) or it is washed out by some other source of IR, such as sunlight.
There are two issues with this raw image: many of the methods that I wanted to use from OpenCV only take 8 bit images as parameters, and the errors created ugly splotches and noise that messed up the algorithms used later on. At first I tried rescaling the 10 bit image to 8 bits by dividing by 4, but that threw out a lot of the contrast that I really needed. After looking at histograms of many different videos, it looked like most of the pixels lived in the upper portion of the [0,1023] range. Based off this, I first constrained the pixel values to be between 768 and 1023, and then subtracted 768 from all of them. This left values in the range of [0,255], which is just what we wanted. Since almost all of the pixels are above 768, not much information is lost from clipping. There might be better ways to convert from 10 bits to 8 bits, that don't throw away any useful information, and I'm still thinking of exploring this step more.
After converting to 8 bits, I still had to deal with the 'errors' in the image. For this, I used a method called 'inpainting', where the error zones are filled in from the borders, by replacing each error pixel with a weighted average of the surrounding pixels. Luckily, OpenCV has a very nice implementation of this. The results were very good, fixing both the 'salt and pepper' noise throughout the image, and the large error blotches that randomly appeared, and the consistent ones where the IR light scatters off of hair and other troublesome materials.
These two steps of normalization are taken care of in the method pretty_depth() in processing.py.
Below are the histograms of a typical depth image, the first one of the raw 10 bit image directly from the Kinect (the 2047 error pixels are ignored) and the second one the result of normalization, by constraining to [768, 1023] and then shifting to [0,255] range.

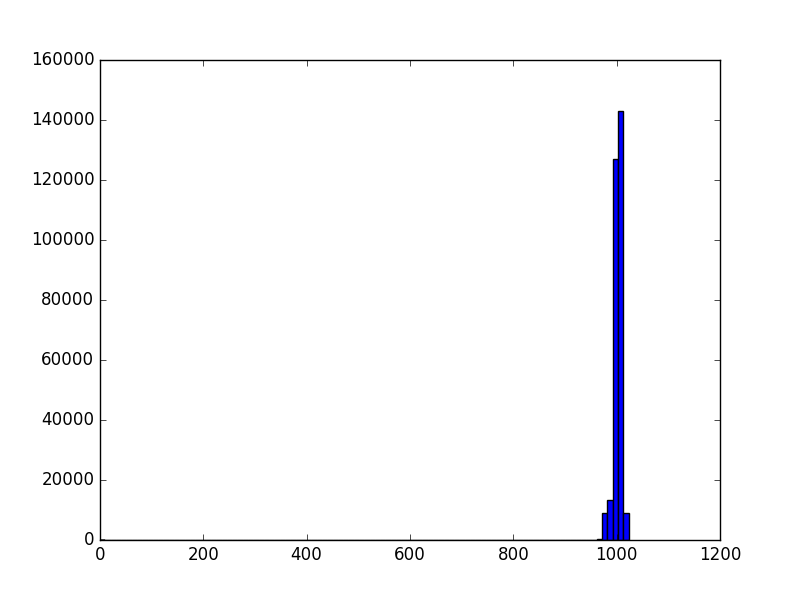
Note that all the pixel values (AKA information) is squashed on the right side of the graph, taking up a small fraction of the valid range from 0 to 1023.
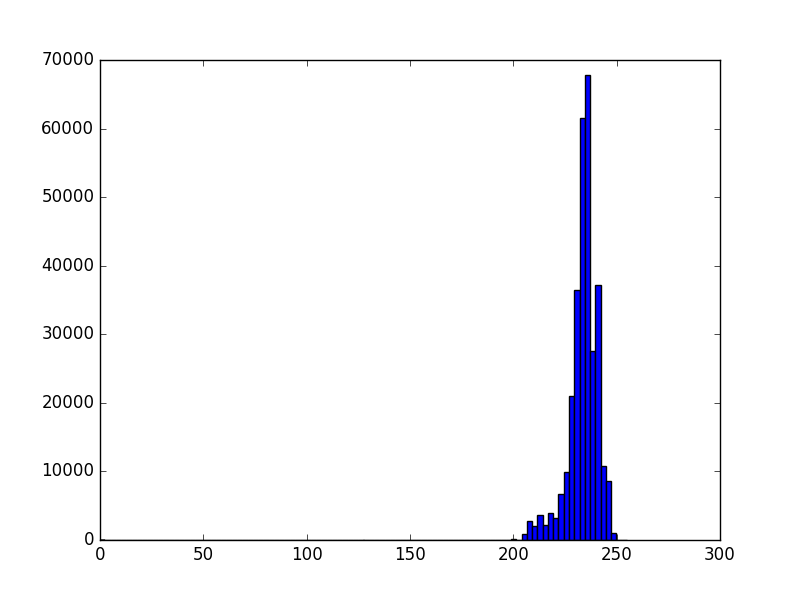
Notice now the pixels and information are much more spread out over the range of 255 values, which gives much better contrast and better signal-to-noise ratio.
Below are two depth videos, both after normalizing to 8 bits (the original images are meaningless, they just appear black, so I didn't bother even putting them in). In the first you can see all the bright white splotches which represent "error" pixels. In the second, inpainting has fixed all of them. Pretty impressive I think!
Climber Detection
After dealing with these petty implementation problems, I got started on the main point of the project: detecting the climber on the wall.
The first idea was to use the raw IR feed from the Kinect, and have the climber wear reflective bracelets and anklets. The IR light from the Kinect's projector would bounce off the reflectors much better than the surrounding wall and clothes, and so the climber's hands and feet could be located by finding the brightest points in the raw IR image. The benefit of this method is its simplicity, but it has many drawbacks. First, the climber is required to wear these bands, which greatly decreases the usability. Also, this method would only be able to locate the wrists and ankles. It would be ideal to be able to determine the whole outline of the climber's body, to check for collisions when dodging chainsaws in games for instance, or in case you wanted to tap a button with your elbow. Even if hands and feet were the only things we cared about, it would still be hard to estimate them accurately from just wrist and ankle positions. Finally, at longer distances, the reflectors had to be oriented fairly well to be picked up, and the strange poses that often are required for climbing made this system too inconsistent.
The second method I tried was background subtraction with the RGB feed. Background subtraction is a technique that uses the assumption that the climber is the only thing moving in the video. It uses a statistical model: Store the last N frames (I used 500), and calculate the mean value and the deviation for each pixel over this time series. Then, each time you get a new frame, compare it to this model. If a pixel's value is further than say, 1 standard deviation from the mean, than it must be a foreground pixel (AKA the climber). Otherwise, it's background. Add this new frame to the model, and throw out the oldest one, and repeat. It's a little bit more complicated than this, using something called a Mixture of Gaussian Model, but that's the basic idea. If you want, you can read the OpenCV docs for the background subtractor.
In certain situations, such as video surveillance software that only records when there's movement, this works really well. However, in this context, where we need to find the outline of a climber very precisely, the shadows created by the bright point lights in the gym mess things up. Modifying the lights in the gym was out of the question, and I wanted the system to be able to adapt to the lighting conditions of any gym, so without some sort of background subtraction that's robust to shadows, this wasn't going to work.
An obvious solution to this problem is to use the depth capabilities from the Kinect with a background subtractor. There are no shadows to worry about in a depth image! However, one problem is that the climber is close to the wall, and so contrast between the climber and the background, especially around the hands and feet, is small. To improve contrast, I used a technique called Contrast Limited Adaptive Histogram Equalization (CLAHE). Similar to normal Adaptive Histogram Equalization, CLAHE looks at the histogram of all the pixel values in the image, and shifts the values of all the pixels in such a way so that there is a nice even distribution of intensities. However, instead of equalizing over the whole image, CLAHE is contrast limited: it performs this operation on small tiles of the image, increasing local contrast without causing global changes. Turns out CLAHE is in OpenCV, and I used that.
I packaged these algorithms into a ClimberDetector class, which is part of the processing.py module.
Below is a depth recording, after normalizing, inpainting, and then applying CLAHE. Note the much better contrast than the same recording above.
>And here you can see the results, overlaid over both the depth and RGB frames. This is after about 80 frames into the recording, once the background subtractor has built up a good model. Before this, there are many parts of the background wall getting erroneously detected.
This is fairly representative of the results. After applying CLAHE, the normal background subtractor does an excellent job finding the torso and upper legs of the climber, and does a worse job with the extremities. Sometimes they are completely missed, like the arms and hands below, and sometimes the limbs are all splotchy, like the legs below. It should be possible to fix the splotches in post-processing, but completely missing the arms needs to be improved. There are many parameters to both CLAHE and the background subtractor that could be tuned better.
Hold Detection
As compared to many other computer vision object recognition tasks, finding the brightly colored, fairly predictably sized plastic holds on the homogeneously colored background wall should be a simple order. The first thing I wanted to do was remove a lot of the complexity of the RGB input images, and get rid of texture and noise. A good tool for this job was OpenCV's pyrMeanShiftFiltering(), which performs a mean shift clustering algorithm on the image, resulting in a sort of 'cartoon' feel. Areas of similar color and texture are all filled with the same value, resulting in nice uniform blobs with sharp boundaries. This result is perfect for performing OpenCV's Canny() edge detection algorithm, which finds the gradient of color change throughout the image, and marks the maximums above some threshold to be edges.
The result is pretty good. There are only occasional false positives, and only the most similarly colored holds are missed. The sharp corners of the actual wall are also picked up, but they can easily be filtered out as being long skinny lines. Although the mean shift filtering algorithm is slow enough that it can't run in real time, it's ok because we can just detect the holds during a calibration period, before the climber ever gets on the wall. I still want to do a lot more work on perfecting hold detection, but this is a pretty good start.

Above: Raw RGB frame.

Above: After applying Mean Shift Filtering to the original picture. It looks like a comic book!
Above: overlay of result of Canny edge detection.

Above: The original image after a simple median blur. Notice that the edges of the holds are blurry.
Overlaying Depth and RGB Frames
The RGB and depth camera on the Kinect are not aligned with each other, and have different FOV's. We need to be able to translate between the two different frames, so that we can do things such as relate the location of a hold detected in the RGB frame to the climber's hand detected in the depth frame. To do this we use OpenCV's getPerspectiveTransform() and warpPerspective() methods. First, we take a picture with the Kinect of a scene that has 4 landmarks distinguishable in both the depth and RGB frame. I used yardsticks stuck up in the air. Then, we find the coordinates of each of these points in both frames, and feed these 8 coordinates into getPerspectiveTransform(). This returns a 3x3 affine transformation matrix that encodes how to rotate, scale, and shear one image to get it to line up with the other. So, to convert an image from the depth frame to the RGB frame or vise versa, we call warpPerspective() with this transformation matrix and the source image. This is very useful for overlaying the mask of the climber, determined from the depth frame, over the top of the RGB image.
In the following image, the green is the mask of the climber found from the depth image. It is easy to see the edges of the depth image, and how the two views align. Notice the smaller field of view of the depth image, and that the view is even a little bit tilted.

Conclusion
In conclusion, I've managed to get some decent climber and hold detection, and have learned a lot about computer vision along the way. The detection isn't accurate enough yet for a real AR game, but with some tweaking it might be able to get there.
Another thought I have is to try to do everything with the RGB camera, and completely toss the depth image. That would be cool because then the project wouldn't rely on the Kinect, and could be built with a Rasberry Pi and cheap webcam! With AI these days, it seems like this should be possible.